
Abstract
INTRODUCTION:
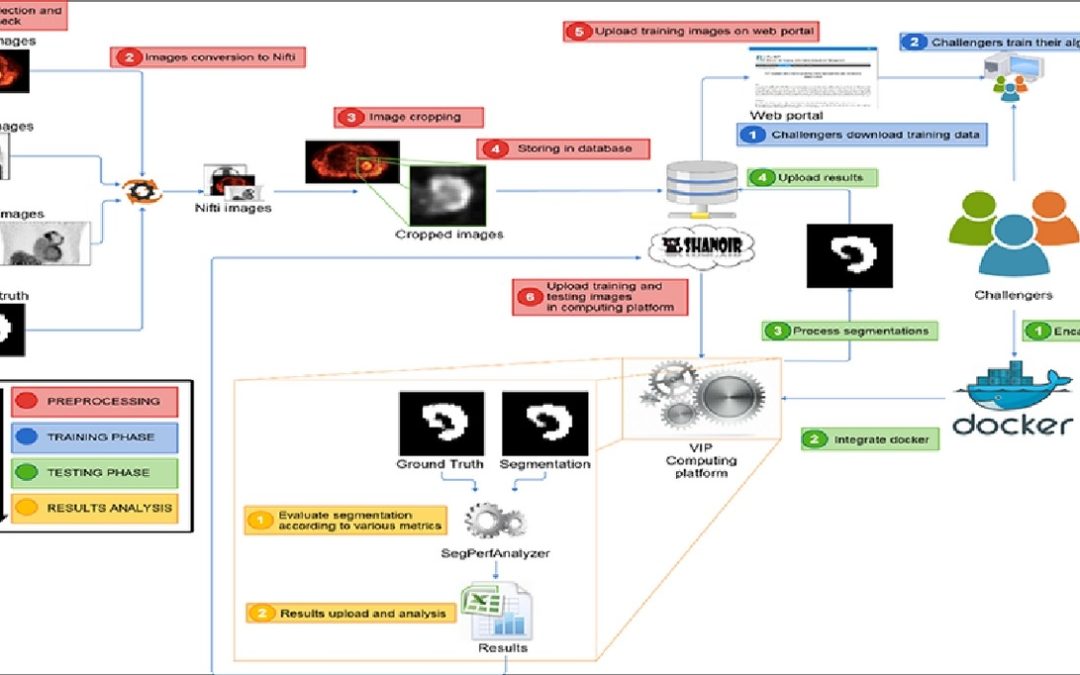
Automatic functional volume segmentation in PET images is a challenge that has been addressed using a large array of methods. A major limitation for the field has been the lack of a benchmark dataset that would allow direct comparison of the results in the various publications. In the present work, we describe a comparison of recent methods on a large dataset following recommendations by the American Association of Physicists in Medicine (AAPM) task group (TG) 211, which was carried out within a MICCAI (Medical Image Computing and Computer Assisted Intervention) challenge.
MATERIALS AND METHODS:
Organization and funding was provided by France Life Imaging (FLI). A dataset of 176 images combining simulated, phantom and clinical images was assembled. A website allowed the participants to register and download training data (n = 19). Challengers then submitted encapsulated pipelines on an online platform that autonomously ran the algorithms on the testing data (n = 157) and evaluated the results. The methods were ranked according to the arithmetic mean of sensitivity and positive predictive value.
RESULTS:
Sixteen teams registered but only four provided manuscripts and pipeline(s) for a total of 10 methods. In addition, results using two thresholds and the Fuzzy Locally Adaptive Bayesian (FLAB) were generated. All competing methods except one performed with median accuracy above 0.8. The method with the highest score was the convolutional neural network-based segmentation, which significantly outperformed 9 out of 12 of the other methods, but not the improved K-Means, Gaussian Model Mixture, and Fuzzy C-Means methods.
CONCLUSION:
The most rigorous comparative study of PET segmentation algorithms to date was carried out using a dataset that is the largest used in such studies so far. The hierarchy amongst the methods in terms of accuracy did not depend strongly on the subset of datasets or the metrics (or combination of metrics). All the methods submitted by the challengers except one demonstrated good performance with median accuracy scores above 0.8.
Full text:
https://www.ncbi.nlm.nih.gov/pubmed/29268169
https://www.sciencedirect.com/science/article/abs/pii/S1361841517301895?via%3Dihub